|
|
| Управление кодировкой текстовых файлов Чтобы обеспечить возможность взаимодействия различных аппаратно-программных платформ, SGML требует, чтобы каждое приложение (включая HTML) явным образом указывало используемый в нем набор символов документа -document character set. Любой набор символов характеризуется двумя составляющими: репертуаром (Repertoire) и способом кодирования позиции (Code positions). Репертуар — это набор абстрактных символов, используемых для записи слов и выражений на соответствующем языке (например, в pcncpiyap могут входить латинский символ «А», кириллический символ «Ы», китайский иероглиф, означающий «воду», и т. д.). Способ кодирования позиции -- это набор целочисленных ссылок на символы, входящие в репертуар. Например, компьютерные системы опознают каждый символ по его числовому коду; так, в наборе символов ASCII коды 65. 66, и 67 ссылаются на символы "А", "В" и "С" соответственно. В настоящее время существует достаточно большое число различных способов кодирования текстовой информации. Некоторые из них возникли значительно раньше Интернета, были стандартизованы и продолжают использоваться в локальных вычислительных системах. Другие же были разработаны специально для обмена данными через Сеть. Наиболее известным представителем первой группы является код ASCII (American Standard Code for Information Interchange - - стандартный американский код для обмена информацией). В нем для кодирования каждого символа используется 7 двоичных разрядов. Набор символов ASCII обеспечивает представление всего лишь 127 различных символов (около 30 служебных, десятичные цифры, буквы английского алфавита и символы пунктуации). Модификацией кода ASCII является так называемый ANSI-код (код, разработанный Американским национальным институтом стандартов - - American National Standard Institute), в котором для кодирования каждого символа используется 8 двоичных разрядов, что обеспечивает представление уже 256 символов. Особенностью ANSI-кода является то, что первые 127 символов он «унаследовал» от ASCII (поскольку они стандартизованы), а вторая половина кода (точнее, половина соответствующей кодовой таблицы) используется в разных странах и разными разработчиками по-своему. Например, в СССР эта часть кодовой таблицы была использована для кодирования символов кириллицы. На сегодняшний день наиболее распространенным вариантом ANSI-кода (в том числе в Интернете) является так называемая «Латиница» (Latin-1) — код, регламентированный международным стандартом ISO-8859-1. Этот код поддерживает практически все западноевропейские языки. Кроме него, в Сети (по крайней мере, в русскоязычной ее части) также достаточно широко применяются следующие ANSI-коды:
Коды ASCII и ANSI зачастую оказываются недостаточны для глобальной информационной системы типа Интернета, поскольку ни один из них не обладает требуемой «многоязычностью». Поэтому HTML использует более совершенный набор символов, который называется «Универсальный набор символов» (Universal Character Set — UCS). Параметры этого, кода определены в стандарте ISO-10646. Он обеспечивает использование набора из нескольких тысяч символов, позволяющих представить символы, используемые практически во всех языках (в том числе и в профессиональных, например, в математике). Такое количество прсдставимых символов объясняется тем, что код UCS является двухбайтовым, то есть для кодирования символов в нем используются 16 разрядов. Набор символов, определенный в ISO-10646, эквивалентен используемому в другом двухбайтовом коде - - Unicode. Оба эти стандарта пополняются время от времени новыми символами, и относительно принятых изменений следует консультироваться на соответствующих информационных узлах Сети. Огромное количество символов, прсдставимых с помощью двухбайтовых кодов, не позволяет применять для этих кодов простейший алгоритм кодирования, основанный на методике «один байт- - один символ». В некоторых случаях с целью упрощения алгоритмов кодирования и сокращения затрат времени и памяти на храпение кодовой таблицы вместо полной версии кода UCS используются его подмножества. Один из таких «частичных» кодов - - код UTF-8 (UCS Transformation Format), в котором число байтов, используемых для кодирования символа, зависит от вида символа: для первых 256 символов используется 1 байт, а для «старших» символов - - 2 банта. Сам по себе набор символов документа не позволяет средствам просмотра пользователя (броузеру) правильно интерпретировать документы HTML, поскольку они обычно пересылаются по сети в виде последовательности байтов. Соответственно, для пересылки документа должно быть предварительно выполнено преобразование его символов (character encoding). Средства разработки (например, текстовые редакторы) могут использовать различные методы кодирования документов HTML (то есть способы преобразования символов в последовательность байтов), и выбор метода в значительной степени зависит от соглашений, используемых системным программным обеспечением компьютера, на котором создавался документ. Кроме того, не всегда для всех символов документа применяется один и тот же способ кодирования. В силу указанных причин броузер должен знать конкретный способ кодирования символов, который использовался для преобразования последовательности символов документа в поток байтов. Каким образом броузер может получить сведения об используемом в документе способе кодирования? Основных механизмов три:
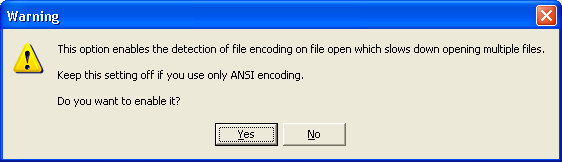
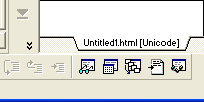
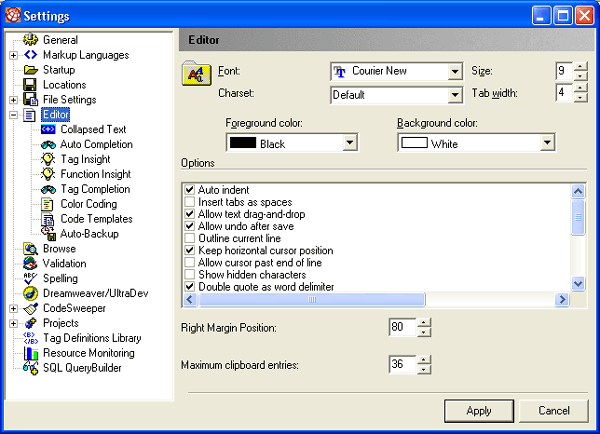
Замечание Кроме этих трех средств, большинство современных броузеров предоставляют пользователю возможность вручную выбрать метод декодирования документа. Ну а самые продвинутые из них пытаются определить кодировку документа с помощью различных эвристических алгоритмов. После столь продолжительного отступления вернемся к HomeSite. Как было сказано в предыдущем подразделе, по умолчанию HomeSite использует для кодирования создаваемых с его помощью документов кодировку ANSI, а именно код ISO-8859-1. Этот же код он использует и для декодирования открываемых документов. Тем не менее, в окне Settings на вкладке File Settings пользователь может разрешить использование не-ANSI кодов, установив соответствующий флажок (см. рис. 1.39). В этом случае при открытии любого документа HomeSite будет пытаться определить используемую в нем кодировку. Для больших документов или при открытии нескольких файлов это может привести к замедлению работы, о чем и предупреждает HomeSite (рис. 1.43). Дополнительно пользователь может указать, что используемый код должен отображаться на этикетке открытого документа (рис. 1.44).
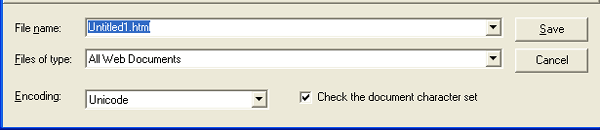
Рис. 1.43. Предупреждение о возможном замедлении работы HomeSite при разрешении использования не-ANSI кодов Разрешение использовать не-ANSI коды приводит также к ряду других последствий. В частности, пользователь может изменить текущую кодировку документа при его сохранении на диске. Поэтому в диалоговом окне Save as становится доступен раскрывающийся список Encoding (Кодировка), который содержит четыре варианта (рис. 1.45):
Рис. 1.44. Представление используемой кодировки на этикетке документа
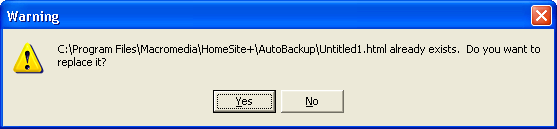
Рис. 1.45. Формат диалогового окна Save as при использовании не-ANSI кодов Расположенный справа от списка флажок Check the document character set Проверять набор символов документа) позволяет указать, должен ли HomeSite при сохранении файла с не-ANSI кодировкой выполнять проверку соответствия гго истинной кодировки (указанной в теге <МЕТА> документа) той, которая выбрана в списке. Если такая проверка выполняется, и было выявлено несоответствие, на экран выводится предупреждающее сообщение (рис. 1.46). В этом случае возможны два корректных выхода из ситуации:
Замечание
Рис. 1.46. Сообщение, предупреждающее о несоответствии кодировки документа его атрибутам
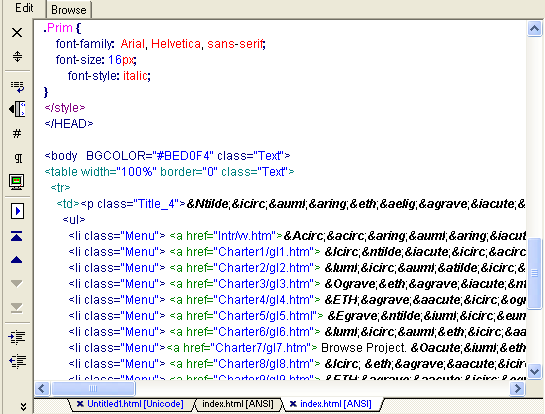
В некоторых случаях (прежде всего - - при конвертировании «обычных» текстовых файлов в HTML-документы) могут возникнуть проблемы с преобразованием кириллических символов. Объясняется это тем, что при выполнении конвертирования HomeSite всегда использует кодовую таблицу ISO-8S59-1. В результате такого преобразования отдельные буквы («д», «ц», «ь») представляются в документе своими именами, причем с западно европейским «акцентом». Например букве «д» соответствует немецкая буква «а умлаут» (то есть «а» с двумя точками наверху). Имена символов начинаются знаком амперсанда и заканчиваются точкой с запятой. В частности, имя символа «а умлаут» выглядит так: ä. Пример конвертированной страницы с именами символов вместо их изображений показан на рис. 1.48. При переключении в окно просмотра имена символов заменяются изображениями символов, однако если используется «не та» кодовая таблица, то текст все равно окажетад трудно читаем. Указанные проблемы позволяет преодолеть специальная функция, которая имеется в составе HomeSite. Она называется Replace Extended Characters (Замена развернутых символов).
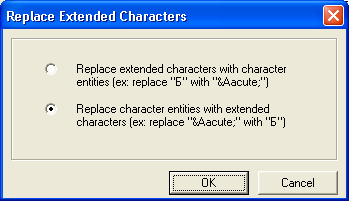
Рис. 1.48. Пример страницы с именами символов Замечание Функция Replace Extended Characters обеспечивает замену имен символов визуальным представлением этих символов, причем на основе системной кодовой таблицы. Чтобы выполнить требуемое преобразование, необходимо:
Рис. 1.49. Диалоговое окно функции Replace Extended Characters |
|
|